Podria parecer que resulta fácil enviar un mail des de Pentaho DI con información relevante, pero de hecho, no lo es tanto. Si que es sencillo enviar un mail con el cuerpo relativamente fijo y un fichero adjunto con datos pero si queremos que los datos aparezcan en el propio cuerpo del mensaje eso ya es otra historia.
Para empezar el mail hay que enviarlo desde una transformación, puesto que los datos los calculamos a nivel de transformación. Si que disponemos de un step para enviar mails, pero no es conveniente pasarle mas de un registro con información, puesto que si lo hacemos, enviará un mail por cada registro, por lo que nos podemos encontrar con el buzón de correo lleno, cuando no bloqueado con un mail por cada registro.
Entonces, voy a proponer una solución, que admito que algo rebuscada es, pero que funciona (si alguien tiene alguna idea mejor que lo diga):
Primer step: Table Input
El objetivo básico es recoger los datos que deseamos enviar en el mail y combinarlos de alguna manera para que se conviertan en un solo registro y por tanto en un solo mail. Una de las formas mas adecuadas de presentarlos seria mediante una tabla HTML. Seguro que hay mas formas pero esta resulta perfecta para presentar varios registros. En mi caso he usado el Table Input para recoger los datos de una tabla que quiero enviar por mail. Para convertir varios registros en uno solo he usado la siguiente estrategia: La select constará de, como mínimo:
1. Dividir la select en 3 selects unidas con "union all": una select para la cabecera , otra para el cuerpo y otra para el pie,
2. La primera select constarà de los tags de inicio HTML, un texto si queremos antes de la tabla i la cabecera de la tabla con los títulos de los camps.
select 'A' id, '<html><body>el texto que queramos independiente de la tabla</br></br><table border=''1''><tr><th>TITULO CAMPO 1</th><th>TITULO CAMPO 2</th></tr>' mail_body from dual
3. La segunda select constarà de los datos, concatenando tags de html antes y despues de cada campo.
union all
select 'A' id,'<tr><td>' || c.campo1 || '</td><td>' || c.campo2|| '</td></tr>' mail_body
from
tabla c
select 'A' id,'<tr><td>' || c.campo1 || '</td><td>' || c.campo2|| '</td></tr>' mail_body
from
tabla c
where
...
...
4. La tercera constarà de los tags HTML para cerrar la tabla y el fichero.
Podemos añadir mas selects con mas texto uniendolas entre si.
union all
select 'A' id,'</table></br></body></html>' mail_body from dual
select 'A' id,'</table></br></body></html>' mail_body from dual
Eso si, cada select debe tener como mínimo dos campos, uno que sea constante, por ejemplo un texto, y otro con las concatenaciones de HTML y campos de información.
Ese campo constante veremos luego para que lo necesitamos.
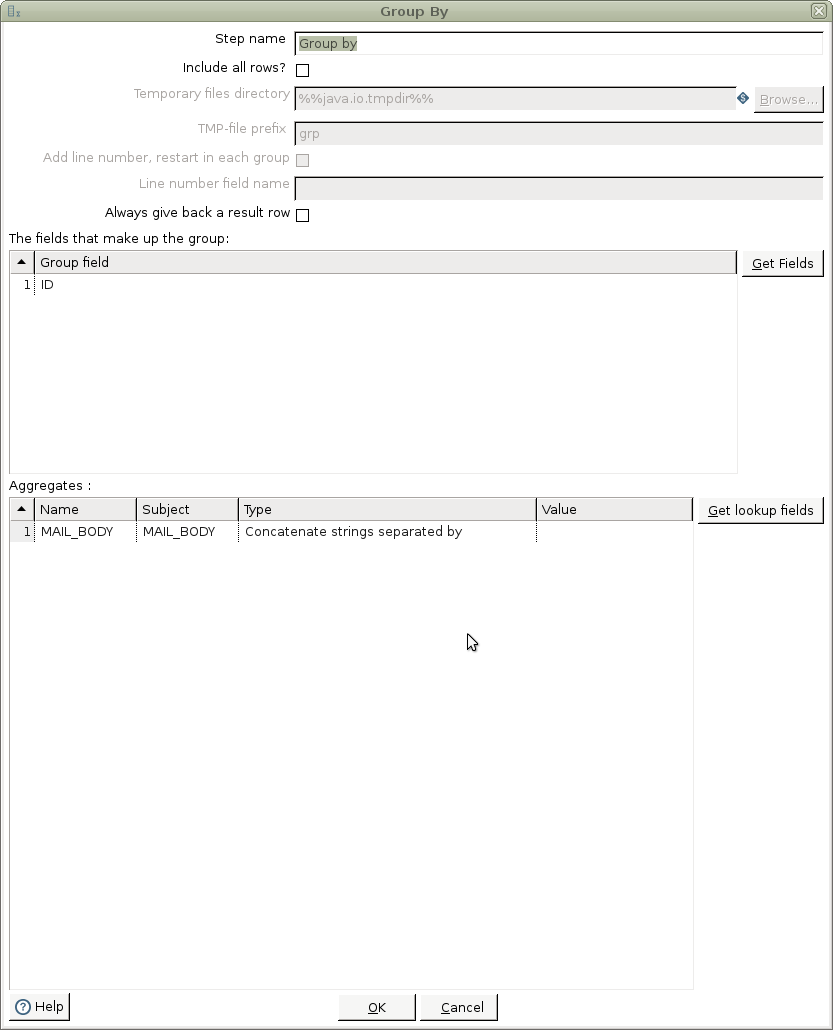
Segundo step: Group by
El campo constante de la select nos servirá como referencia sobre el cual agruparemos el otro campo usando el step group by. Usaremos el tipo de agrupación Concatenate strings separated by:
Tercer step: Get Variables
Este paso no es realmente necesario. Es, sin embargo, una buena práctica el guardar los datos de conexiones, de servidores y en este caso, del servidor de mail, en variables que se instancian en un fichero kettle.properties y se cargan al iniciar el spoon. Pero eso ya es otra historia que será contada en otra ocasión. El caso es que el step de mail necesita datos de conexión del servidor de mail que no se pueden indicar directamente mediante variables en el step mismo, así que antes tengo que capturar el valor de las variables y guardarlos en campos.
Cuarto step: Send Mail
En este paso configuramos el mail que queremos enviar, definimos la conexión al servidor de correo, le indicamos que el cuerpo del mensaje lo contiene el campo MAIL_BODY que construimos en los steps anteriores, le adjuntamos un archivo si deseamos y listo!










{kind=link}