Ahora tocaría llevar a la práctica la teoría explicada en el anterior post. Pero como no es posible tratar las particularidades de cada caso, vamos a dar solo unas pinceladas, sin entrar en detalles.
Tal como expliqué en el anterior post, para no inventar de nuevo la rueda, nos basaremos en el proyecto TestKitchen, cuyo código fuente usaremos como base para nuestro sistema. Por tanto, conseguiremos ese código fuente añadiendo a nuestro IDE favorito el repositorio Subversion que nos ofrece la página del proyecto:
http://code.google.com/p/testkitchen/source/checkout .Con el checkout correspondiente obtendremos el código en nuestro workspace local.
Una vez tenemos el código podemos ver que tiene las siguientes partes:
El primer nivel del proyecto está formado por las carpetas bin, dist y src. En src encontraremos el código fuente del proyecto. En dist encontraremos un espacio de trabajo donde poner nuestros proyectos de test y bin permanecerá vacio. En la raiz tenemos el build.xml y demás ficheros de configuración que nos permiten compilar el proyecto. Vamos allá.
Para ello necesitamos instalar apache-ant en nuestro sistema. Vamos a su página web y descargamos la versión mas reciente.
http://ant.apache.org/
Una vez instalado (establecido las variables de entorno PATH y demás) podemos empezar a probar la compilación. Para ello configuramos el IDE para ejecutar ant para este proyecto, o bien, desde un terminal nos situamos en la carpeta raiz del proyecto (donde esta el build.xml) i ejecutamos:
> ant jar
El compilador gracias a ivy, buscará las dependencias y descargará aquellos paquetes que sean necesarios. Es probable que aparezcan errores por dependencias insatisfechas. Es aquí donde hay que ajustar los ficheros de dependencias para que nos baje aquellos paquetes que necesitemos o añadir las dependencias que sean necesarias en nuestro caso específico. Aquellos que no encuentre quizás tengamos que añadirlos a mano, como por ejemplo el driver jdbc de Oracle. En mi caso, modifique el código fuente, la clase KitchenTestCase que tiene métodos para ejecutar las transformaciones y trabajos de Pentaho. Por ejemplo, las transformaciones y trabajos que queremos testear estan en la carpeta dist/ETL/ .Podemos modificar el código para que los busque en otra carpeta, o incluso en un repositorio de kettle de bd.
Una vez compilado (no sin muchos problemas) empezamos a crear nuestro proyecto de test. Para ello nos situamos en la carpeta dist i ejecutamos el siguiente comando:
ant -Dproject=<nombre del proyecto> create-project
Esto nos creará una subcarpeta con el nombre del proyecto en la carpeta dist/projects. En su interior tendremos las carpetas:
En datasets tendremos que poner los ficheros XML con datos de prueba y datos de comprobación.
En deltas pondremos scripts SQL de preparación de bd.
En tests pondremos las clases que realizaran los tests unitarios.
A su vez, en la carpeta dist/ETL/ se crea una subcarpeta con el nombre del proyecto donde pondremos las transformaciones (ktr) y los trabajos que deseamos testear.
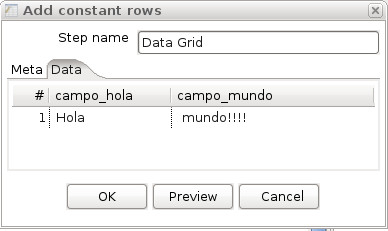
Editamos los ficheros XML con datos de prueba que serviran de entrada a nuestra transformación. Cada tag corresponde a un registro de entrada y lleva por nombre el nombre de la tabla, y sus atributos corresponden a los valores que adoptan los campos de ese registro.
Tambien creamos un XML con los datos esperados, del mismo modo que el anterior pero correspondiente a la tabla de salida de la transformación.
Creamos una clase heredada de KitchenTestCase con el nombre terminado en Test y modificamos aquello que sea necesario. Por ejemplo, los nombres de ficheros, las cargas de los mismos, las conexiones a la base de datos. Por mi parte he decidido no utilizar jndi y sustituirlo por una conexión jdbc normal.
Una vez preparado, para pasar el test ejecutamos el siguiente comando:
ant -Denv=test -Dproject=<nombre del proyecto>
Nos devolverá el resultado del test. ¿Que ha sucedido?. La classe <nombre>Test tiene varios métodos:
- Initialize: En este método utilizamos métodos de dbdeploy para cargar la tabla de entrada de la bd, que nuestra transformación usarà, con los datos del fichero XML. Ejecuta la transformación o el job usando métodos de la API de Kettle. Esto nos pondra en la tabla de salida los resultados de la ejecución de la transformación o el trabajo.
- test<nombre transformacion>: Carga el fichero de datos de comprobación y los compara con el resultado de ejecutar el trabajo/transformación.
Como he dicho antes, no pretendo entrar en detalles concretos, puesto que cada caso particular requiere modificaciones concretas, y sin duda, tendreis que pelearos con mas o menos problemas para que todo funcione.






{kind=link}